
In this article, we built a real-time data pipeline that captures YouTube comments, streams them through Apache Kafka, and then processes and filters the data with Flink. The processed data is stored in MongoDB for deeper analysis.
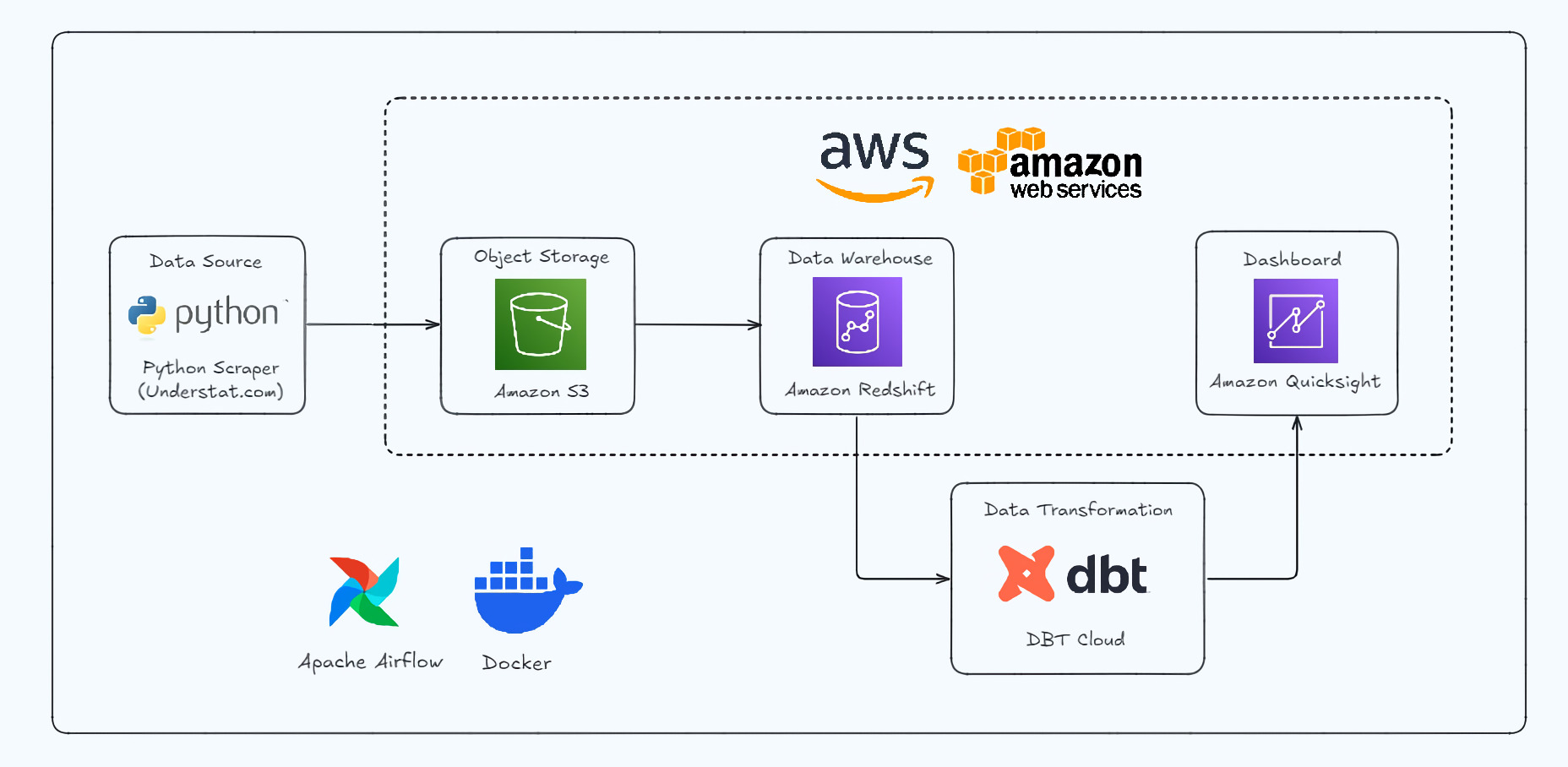
This project automates the collection, processing, and visualization of football data from Europe’s top leagues using a modern data engineering stack. Python handles scraping, Airflow orchestrates workflows, S3 and Redshift store and query data, dbt Cloud transforms it, and QuickSight provides interactive dashboards for actionable insights.
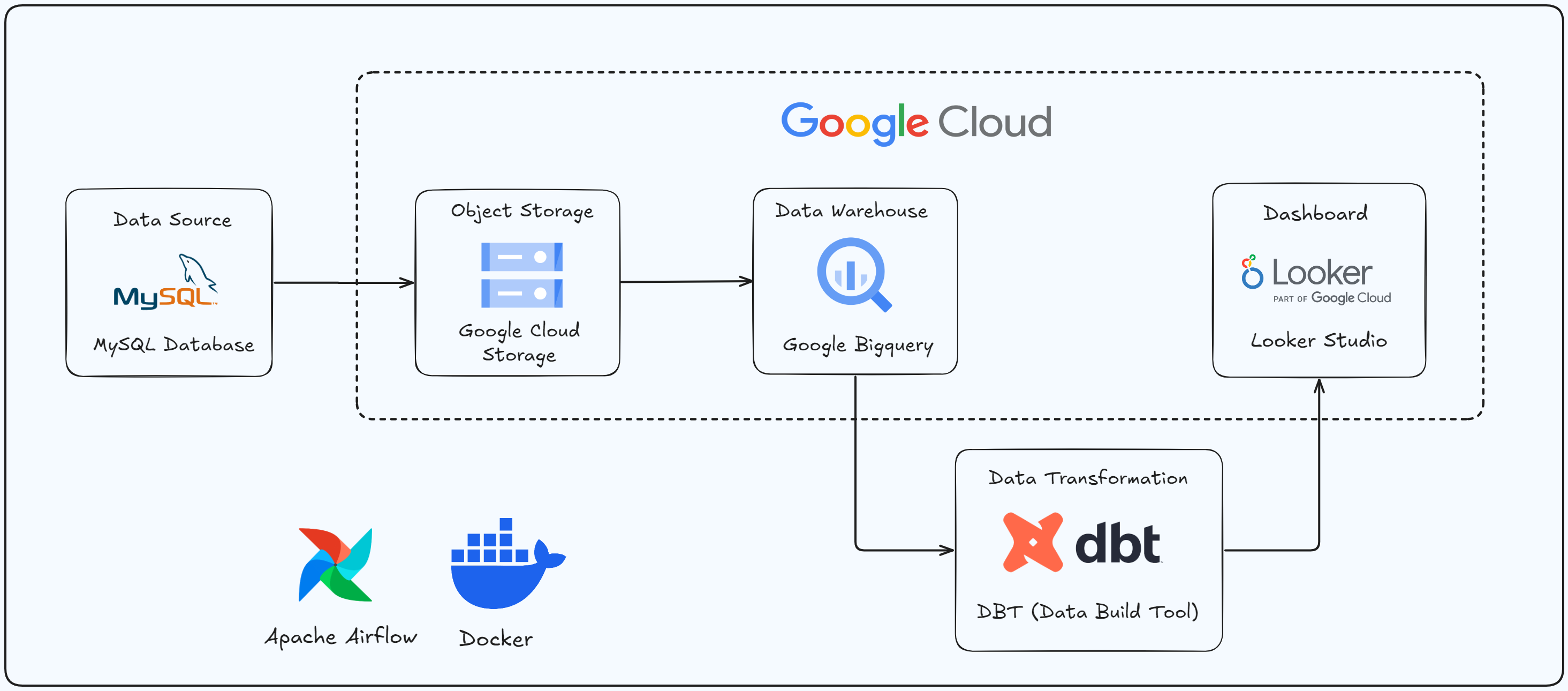
This project builds an automated, scalable ELT pipeline on Google Cloud Platform. Data is extracted from MySQL, stored in Cloud Storage, transformed in BigQuery using dbt Core, and visualized in Looker Studio to reveal sales insights, with Apache Airflow ensuring end-to-end automation using the Amazon Products 2023 Kaggle dataset.
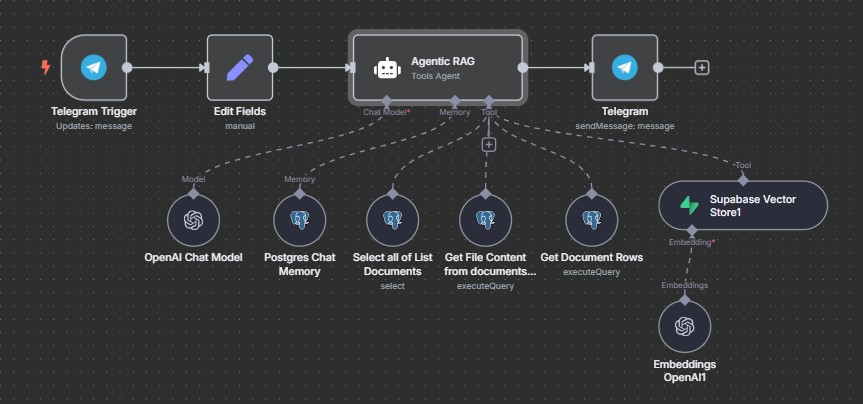
Traditional RAG is like a smart librarian who finds books but doesn’t fully understand your question. Agentic RAG is like an assistant who not only finds the right books but also reads, analyzes, compares facts, and uses the right tools to deliver the best answer. In this project, we introduce planning, reasoning, memory, and tool selection into the RAG process. The chatbot acts more like an intelligent agent, thinking before answering.
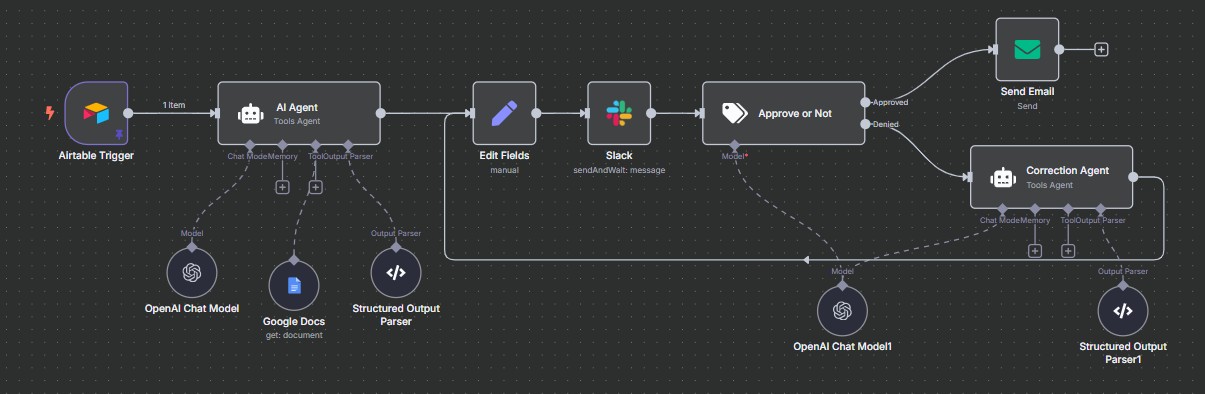
Traditional automations act like a machine: they execute tasks blindly. AI Sales Agents, on the other hand, act more like human sales reps, classifying, reasoning, generating personalized emails, and improving through human feedback. In this project, we integrate lead classification, AI-generated emails, human-in-the-loop validation, and cross-platform communication using tools like n8n, Typeform, Airtable, Slack, and SMTP email.